



Table of contents
Libraries
ExpressdotenvTo manage environment variables inside.env file.env variableis a variable outside the program built inside the OS through some functionality.http-status-codes
Detailed desc on what all ports are running in our system Above pic then kill -9 / process id>
npm will --save by default now.
As most of the time we are going to make API driven applications and API versioning is tehnically important. Inside our routes we will be having routes in diff folders for diff versions. Every different version of API routing, wherver the registration of API's we have to do, we are going to do it in diff set of folders. This will help us to do API versioning easily.utils used to store common helper functions.
Whenever we will deploy, either we will write a script to manage the env variables or we will manually make a .env file.
If you have node above version 18 you can use node --watch. But if you have a lower node version, you can use nodemon. On file change it will restart the project.
The command to run is npx nodemon src/index.js .npx : If you have any package that you want to directly execute out of the js file. for ex: in your terminal, you want to directly execute any package like nodemon you can use npx .
Writing this npx nodemon src/index.js maybe cumbersome to do. So we are going to write this inside scripts in package.json .
Let's We will be having separate ways to run things in say development environment, in production environment, we can use diff commands.
'/api/v1/blogs' : Why are we prepending api here ? There can be 2 type of routes. 1 type can be API driven routes where somebody can use them as an API. SOme can be non-api routes for example if we want to render a home page from same express server.
Express Routers
Routing refers to endpoints (URLs).
If you want to make a URL that is independent of what type of http method you are passing then you can use app.all()
If we want to establish a middleware that should be applied to all of the routes written below it we can do app.use()Mounting means registering or establishing
If you have to modularise your routings into separate folders for I would say entities & everything then we can make an express router you can do route instead of doing app.get, app.post we can do router.get, router.post & we can export that router.
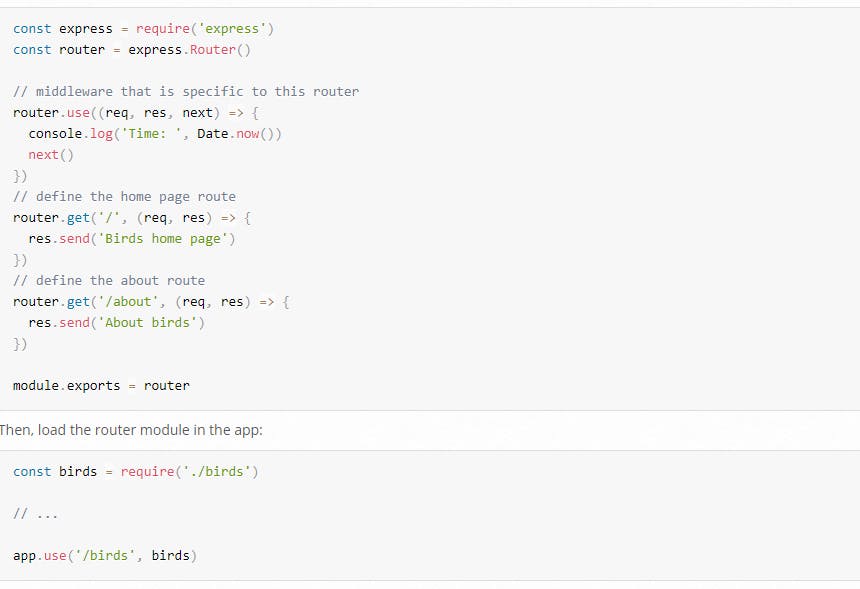
Once you have exported that router, then at any point of time if you want to have a url, let's say prefix of url & you want to mount a particular routes after that you can actually do that.
app.use Using this we can register more middlewares. If we want to register a middle ware for all of the routes somewhere, we can use this& pass the middleware. It does 1 more thing. It can help us to mount a router.Router It's an express class that can help you to create modules for your routes.
URL is used for the complete web adress. ex: booking.com/booking. This complete adress refers to URL.
URI just refers to the resource part. ex: /booking, /users, /blogs.
The whole purpose of using express router is that you can segregate your routes into separate folders.
Definitely you can have some SSR based layouts if you want to have some layout based routes, you can have some prefix for that. Can define it yourself.
Generally when we have some api responses, we try to make some common API structure.
In express, we have a very cool way of defining status codes. In the response object, we can say response.status(500).json . The response object has a status function. This status function actually sets the status code & this status function returns the same response object & on that response object we have the json function. The response object has a JSON function. When we will be doing unit testing this piece of information will be required to mock all of these.
winston-npm: NPM library for logging. We will manage a small log file. Winston provides you a bunch of formats in which you can do your logging. It takes callback function as an argument
What we are doing? We have all of these objects. create logger is a function, rest 2 are objects. Then we destructure your format object where we get lable timestamp & all those functions.
printf helps to print a aparticular log. It actually takes a function as an argument. So it takes a callback function as an argument. Inside this callback function, we get an object which we can destructure ( will get level, message & timestamp.
Level is the severity level.
Now we are going to creat a logger function createlogger. Inside createlogger we will pass an object. we have a format. In format there is a function called combine. we need to pass combine function. This combine function takes a timestamp. In timestamb also I can mention the format of timestamp.
transports We want our logs to be printed on the console also. & let's say for later debugging, you want your logs to be stored in some log files as well. So what we can do is we mention all the streams where we want to actually put your logs inside the transport array.
new.transports.console() This mentions that if you will use winston it will only print on the console. I f we use another transport transport.file & then you pass a custom object with the filenames as ( there's a filename property) combined.log as we just want combined logs in 1 file.
If anyone will use logger function the logs will come in console and file both.
To use, just call the corresponding logger function. Once you have callled you just need to pass ( for ex what is the actual error code)
logger.inof Here info is the level. Anywhere, anytime, we have to use a log, we can do logger.error or logger.info, out loggers will work
ORM
ORM is for SQL databases. ODM is for NoSQL databases.
When you write SQL, when you have to interact with your SQL databases. then we write something like create table tablename. All of this is a Sequelish syntax. It's not object-oriented, right? Ofcourse we are fond of doing things object oriented. Anywhere at any point we do something like new object or object.some message we understand the code better. ORM actually acts as a bridge between mySQL syntax & object oriented syntax & what it does is, it provides us an interface using which you can write object oriented code which will internally be automatically be convereted into a SQL based code & then it will execute your SQl. For ex : if we have to do insert into Product instead of that we can do product.create Mongoose is an ORM for MongoDB. It gives a promise-based syntax. It helps us to define our schema & models as well. For ex: how our user table should look like .
It helps us to do data modelling for ex: how our schema should look like .
We can do associations. for ex: 1 to many, many to 1
A category has many products. We setup this association using Sequelise. Now if we want all the products of a category, we don't need to write a join. We can just say category.getProducts. It will give all products.
A lot of things are pretty optimised in ORMs.
Apart from installing Sequelise, we need to install a driver. Sequelise has an ORM for any type of relational database. How sequelise will know which type of database to connect & how to connect because there can be different databases. So for that we need to use a driver. like saying in my project I will connect to a mySQL database
Whatever database we are using , it needs a driver to make a connection from the ORM layer to the actual database layer because there are diff databases, not every database has the same way to do the connection or do the queries & everything. Every database maybe exposing diff ways of optimisation & diff ways of doing queries.
Node-based ORMs are not that powerful compared to Rails-based ORMs.
What happens in Routes? We actually try to modularise our route registration & controller bindings. So we use the express router because the express router helps in segregating out routes in diff modules & then club them together wherever we want.
The use of the controller is to collect request & forward it somewhere else.
The essence of the express Router object is that you don't need to first pass your express app server object. You make a new router object. You make registrations using the router object.

If your incoming URL/route starts with /v1 we are going to mount or bind the v1Routes router object with /v1 . After /v1 everything will be handled by v1Routes.
In the main index.js file, we don't need to make an express router, we have access to app object. We can say app.use() i.e at any point of time if incoming request start with /api then I'm going to bind apiRoutes router object to it.
Action Controller is the C in MVC. After the router has determined which controller to use for a request, the controller is responsible for making sense of the request and producing the appropriate output. Luckily, Action Controller does most of the groundwork for you and uses smart conventions to make this as straightforward as possible.
For most conventional RESTful applications, the controller will receive the request (this is invisible to you as the developer), fetch or save data from a model, and use a view to create HTML output. If your controller needs to do things a little differently, that's not a problem, this is just the most common way for a controller to work.
A controller can thus be thought of as a middleman between models and views. It makes the model data available to the view, so it can display that data to the user, and it saves or updates user data to the model.
"Modularity means being able to segregate your routes and their mounting (mounting means registration) into separate modules.
The routes folder's sole responsibility should be the registration of routes and making them mountable, so that if someone wants to mount them to another URL, they can.
Install Sequelize: Sequelize is an ORM (Object-Relational Mapping) tool. It helps convert your RDBMS-based SQL queries into object-oriented code.
Install the MySQL driver: We are ready, but if we start reading the Sequelize documentation, there is a lot of code setup required for Sequelize. It involves several steps that we don't need to do. Fortunately, Sequelize provides a supported package called
sequelize-cli.Install Sequelize CLI: Sequelize CLI provides a set of commands that are consistent with commands used in other frameworks. One of these commands is
sequelize db:migrate, which is similar to therails db:migratecommand in Rails. Sequelize CLI automates many tasks, including database configurations and file generation.
Our actual coding implementation will be inside the src folder, where all the logic resides. Use the sequelize init command to initialize a Sequelize project. It also handles database and configuration logic automatically. When creating models, seed files, and seeders, it generates the necessary code. We don't want the code to clutter the root folder because all our logic is in the src folder. Navigate to the src folder and initialize Sequelize.
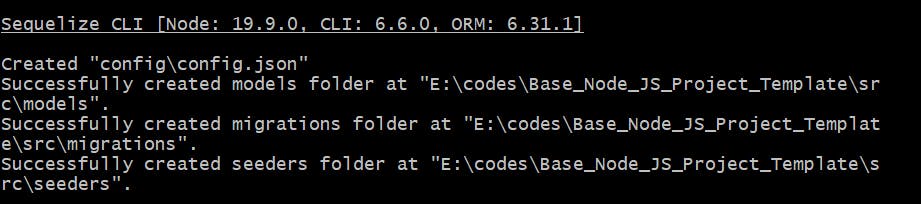
Once initialized, it performs the aforementioned tasks. With this integration, most of the folder-related setup is complete.
config.json: This file provides configuration for three environments: Development, Test, and Production.During local development, we create and edit tables, so we use the dev databases. It's not advisable to use production databases for such tasks.
QA testers need a separate environment, the test environment, to test features independently from the development environment.
When everything is ready, we roll out to the production environment.
The default environment is detected automatically.
The
dialectspecifies which database to connect to.hostrefers to the URL of the server where the MySQL server is deployed. By default, it uses port 3306, the default MySQL port.databaseis the name of the database to be created.
seeders: If you want to populate default values in your database, such as testing with some products in an e-commerce API, seeders are used. Instead of manually inserting data or using an API, seeders provide a way to add seed data (initial data) to your tables. They are primarily used for testing purposes. For example, if you need to assign roles (e.g., normal user, seller, admin) that exist across development, test, and production environments, you can create a seeder file for roles. Running the seeder file will automatically populate the roles in your database. Seeders are useful when you have a set of data that remains constant in the table.
Migrations: Migration files are used for version control of your database and are utilized in many frameworks.
You start by creating a small database for your app.
As you add more features, you update your database by adding columns, tables, indexing, views, joins, etc.
If you ever need to revert to an older version of the database, migrations come in handy.
Migration files are simple scripts, usually JavaScript files if you're using Node.js. They allow you to programmatically manage versions of your database. Each version has a unique ID.
Running
db:migratecreates a new version of your database.migration:generatecreates a new migration file where you specify the changes you want to make. It automates many tasks, such as syncing, for you."
I would like to acknowledge the valuable guidance and instruction provided by Sanket Singh in helping me understand and resolve the issues mentioned above. His expertise and teaching have been instrumental in improving my skills and knowledge.