Project Features

Technology is not only the thing that moves the human race forward, but it’s the only thing that ever has. Without technology, we’re just monkeys playing in the dirt.
Facts digestion from the last class
The majority of the code written inside the models is generated by the sequelize CLI. We only need to make some edits and changes, such as specifying constraints and attributes using sequelize CLI commands.
Repositories act as the layer that interacts with the database. They contain the sequelize code necessary to create entries in the database.
Services communicate with repositories to perform database operations. They return response objects that include information from the models, like the example JSON below:
JSONCopy code{
"id": 2,
"modelNumber": "airbus a320",
"capacity": "180",
"updatedAt": "2023-05-22T07:33:01.455Z",
"createdAt": "2023-05-22T07:33:01.455Z"
}
Controllers interact with services and structure data in a format that is ultimately sent to the repository. The repository then uses sequelize commands to insert data into tables and responds with a formatted response.
Routers communicate with controllers, handling the routing logic for the application.
In
index.js, we establish communication with the routers to set up the application's endpoints.
Even if the user didn't provide the correct value, our code was displaying an Internal Server Error. To address this, we implemented an authentication check in a middleware to send a Bad Request (400) response instead.

One aspect of the current coding implementation that I find cumbersome is the repetitive preparation of similar JSON structures. We constantly have to create a JSON object with properties like success: false and data:{}. The only things that change are the message and error parts.
To address this, we can introduce a response object and an error response object. By configuring the error property and message property of the error response object, we can consistently throw that error response object whenever an error occurs.
Additionally, instead of sending a custom object in the middleware, it would be better to have a dedicated error object for consistency. We could create a common error class by making an app-error file inside the errors folder in the utils directory.
In the errors/app-error.js file, we can define an AppError class that extends the built-in Error class in JavaScript. This AppError class can serve as the base for our custom error classes.
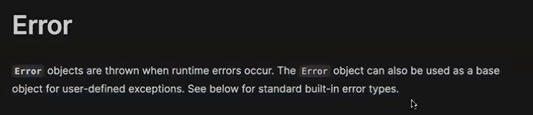
Using custom error classes will ensure more consistent and meaningful error messages for users. We can create different error classes for client errors and server errors, improving the overall error handling in our project.
When working in a company, implementing an API involves multiple levels of development. For example, before implementing the API, we typically prepare documentation outlining its specifications. This documentation includes details such as the URL, the associated controller, and the type of request (GET, POST, etc.). We submit this documentation in a pull request.
Once the pull request is submitted, we can begin implementing the API. Ideally, each API should be implemented in a separate pull request, including test cases and unit tests specific to that API. This approach ensures a more organized and manageable development process, with separate pull requests for CRUD operations like Read, Write, Delete, and Update.
Currently, our project setup handles errors but does not provide informative and meaningful error messages. By creating a class and consistently throwing objects of that class, we can improve the error handling and provide more informative errors.

The detailed explanation of what happened during the current call can be found in the explanation property of the error object.
The Error class in JavaScript has a function called captureStackTrace, which allows us to capture the stack trace (the sequence of function calls leading to the error). We can use this stack trace for logging purposes.
We can also create a custom JavaScript object that will be frequently used in our code.
In the current implementation, we are using try-catch blocks everywhere and re-throwing the error to the upper layer. The purpose of this approach is to log the exact situation in which the error occurred. This could be easily achieved using error.captureStackTrace.
In the airplane-controller.js file, it is not advisable to hardcode the status codes. The error object already has a statusCode property, as we set it in the new AppError instance in the airplane-service.js file. The controller doesn't need to handle this logic; it can simply embed the provided status code from the error object.
The controller's role is to pass on the error to the next layer, while most of the error handling logic resides within the service.

Translation or internationalization is crucial when sending backend error messages to clients, especially in scenarios where the client application supports multiple languages. Typically, a separate translation service is implemented in the backend to handle this.
The seeders folder is significant during testing, as it allows us to initialize the database with a few basic pre-defined values. For example, if a table only requires a fixed set of values, we can prepare seeders to populate the table quickly. To generate a seeder file, navigate to the src directory and run the command: npx sequelize seed:generate --name add-airplanes. This will generate the necessary file structure. Inside the up function of the generated file, we can insert the desired entries using a bulk insert. To seed the database with all the created seeders, run npx sequelize db:seed:all. The undo command, npx sequelize db:seed:undo, can be used to remove the seeded entries.
For instance, if we have a table that defines user roles in an e-commerce application and these roles rarely change, we can use seeders to populate the roles table. This can save time and simplify the process, especially during local development or when sharing the project with others.
Migration refers to managing the versioning of the database schema.




